
我院两篇论文被人工智能领域顶级学术会议AAAI 2025接收
山西大学大数据科学与产业研究院两篇论文《k-HyperEdge Medoids for Clustering Ensemble》、《Sharper Error Bounds in Late Fusion Multi-view Clustering Using Eigenvalue Proportion》被人工智能领域国际顶级会议AAAI 2025接收。
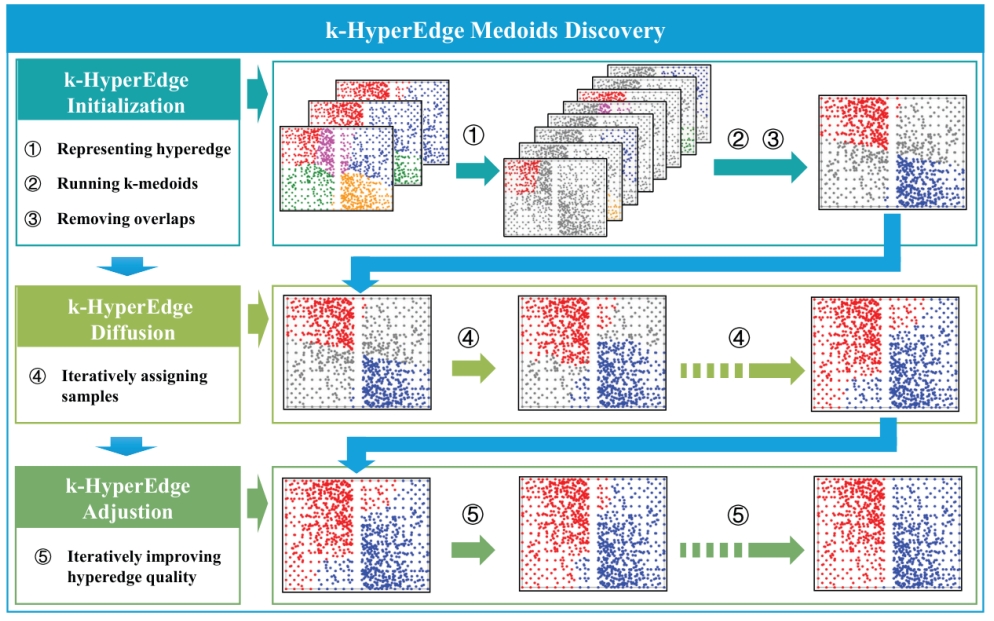
论文名称:《k-HyperEdge Medoids for Clustering Ensemble》
论文作者:李飞江,王婕婷,张镏雅,钱宇华(通讯作者),靳帅,闫涛,杜亮
论文介绍:聚类集成能有效提升单一聚类的性能,目前研究者已提出了大量聚类集成方法。这些方法可大致分为类簇视角下的方法和和样本视角下的方法。类簇视角下的方法总体上效率较高,但会受到不可靠基础聚类结果的影响。样本视角下的方法性能优异,但构建样本共现关系耗时较长。本工作将聚类集成问题为视为k超边代表发现问题,并提出了一种基于 k超边代表的聚类集成方法,该方法考虑了上述两类聚类集合方法的特点。在该方法中,先在类簇视角下选取一组代表性超边,然后从样本视角调整超边,从而构建k超边代表集合,最终集成结果即为k超边代表。理论分析表明,所提调整方法近似达到最优,所提分配方法可以逐步降低损失函数。人造数据实验显示了所提方法的工作机制。在20组真实数据上的分析实验验证了所提聚类集成方法的收敛性、有效性和高效性。
论文名称:《Sharper Error Bounds in Late Fusion Multi-view Clustering Using Eigenvalue Proportion》
论文作者:杜亮,蒋恒辉,李晓东,郭乙青,陈艳,李飞江,周芃,钱宇华
论文介绍:多视图聚类的目标是整合多视图的互补信息以提升聚类效果。然而,现有的后期融合多视图聚类方法在处理噪声和冗余分区时表现不足,且难以捕捉视图间的高阶相关性。为了解决这些问题,本文从理论上分析了多核k-means的泛化误差界,利用局部Rademacher复杂度和主特征值比例,推导出收敛率为O(1/n)的误差界,优于现有的 O(\sqrt{k/n}) 的收敛率。基于这一理论分析,提出了一种在多线性k-means框架中引入低通图滤波的策略,以减弱噪声和冗余同时优化主特征值比例,从而提升聚类准确率。实验结果表明该方法在多个基准数据集上的性能优于同类方法。
AAAI(AAAI Conference on Artificial Intelligence)是国际顶级人工智能学术会议之一,是人工智能领域的主要国际学术组织人工智能促进会(Association for the Advancement of Artificial Intelligence, AAAI)的年会。
撰稿人:李飞江、杜亮;一审:贾 佳;二审:钱宇华